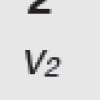Almeno per chi scrive questo articolo, uno dei falsi che più hanno influenzato la storia occidentale è il documento (fasullo) della “Donazione di Costantino”.
In base a questo testo Costantino avrebbe conferito al papato insegne e dignità imperiali, nonché il potere sovrano sulla città di Roma, su tutta l’Italia e sulle regioni occidentali dell'impero, e avrebbe trasferito la propria sede e il proprio dominio in Oriente. Questo documento è stato più volte utilizzato per avvalorare le pretese di potere del papato addirittura in epoca tarda sulle nuove terre scoperte dell’America.
Anche se la sua autenticità era stata messa in dubbio già in precedenza, verso la metà del 1400 l’umanista Lorenzo Valla con l’opera La falsa donazione di Costantino (titolo che nell’originale latino è De falso credito et ementita Constantini donatione decmalatio) dimostrò che il documento a fondamento della presunta donazione dell’imperatore Costantino a papa Silvestro era un falso.
Lo studioso Valla arrivò a questa conclusione a partire da una analisi filologica sul latino contenuto nel testo (che dimostrò essere di epoca successiva rispetto alla sua presunta scrittura) e con considerazioni di tipo storico. Nel testo, per esempio, era presente un riferimento alla città di Costantinopoli, che alla morte di Costantino era ancora in via di costruzione e solo successivamente prese quel nome in onore dell’imperatore ormai morto.
In generale l’analisi filologica dei testi è una disciplina ampiamente affermata, che analizza testi per mezzo di tecniche di tipo qualitativo.
L’importanza e la profondità dell’analisi filologica non è però il tema di questo articolo, ma rappresenta un ideale punto di inizio.
Una delle domande che immaginiamo a questo punto un lettore di Query potrebbe farsi è se esistono delle tecniche quantitative che possano affiancare quelle qualitative. La risposta è sì e in questo articolo ci proponiamo di spiegare alcuni degli strumenti matematici che vengono utilizzati.
Vedremo infatti che, in parallelo alle metodologie generalmente utilizzate da ricercatori di formazione umanistica, si è affiancato a partire dalla seconda metà del Novecento un approccio di tipo quantitativo all’analisi dei testi.
Ovviamente per poter analizzare testi molto ampi fra loro con tecniche quantitative di tipo statistico-matematico, è stato necessario il parallelo sviluppo delle capacità di calcolo che solo computer via via sempre più potenti potevano garantire.
Queste tecniche quantitative, sviluppate in modo analogo a quelle qualitative, hanno come obiettivo quello di analizzare in modo statistico le caratteristiche dei testi, a partire, per esempio, dalla frequenza di alcune parole in grandi raccolte di dati.
In particolare, utilizzando strumenti matematico-statistici, è possibile realizzare l’attribuzione autoriale di testi che per vari motivi sono anonimi, ma che si ipotizza siano stati scritti da un certo autore; oppure è possibile capire se quel testo è un plagio o, infine, con quale probabilità un certo testo è stato veramente scritto dal tal autore.
La matematica offre quindi uno strumento per scoprire dei plagi e magari anche dei falsi documenti.
In un’epoca di diffusione dei testi tramite internet, le applicazioni possibili sono ovviamente svariate e includono la possibilità di scoprire plagi di ricerche da parti di scienziati, così come di codici di programmi.
Un piccolo passo indietro: l’era dei computer
L’idea di analizzare in modo statistico i testi e il linguaggio in cui sono scritti viene in genere attribuita a lavori degli anni ’40 del Novecento, quali quelli di G. K. Zipf e G. U. Yule (si veda[1], [2]). In particolare, dal primo prende il nome la legge empirica di Zipf, secondo cui la frequenza di una parola in un testo sufficientemente lungo è inversamente proporzionale al suo rango, ovvero la posizione occupata da una parola in un ordinamento di frequenza discendente.
A partire dagli anni ’50-’60, queste idee vennero riprese e sviluppate. Particolarmente interessanti sono state le ricerche di Roberto Busa[3], un gesuita che aveva come obiettivo quello di studiare l’analisi dei lemmi dell’opera omnia di Tommaso d’Aquino. Resosi conto dell’impossibilità di un’analisi manuale di tale mole di testi, Busa si rivolse all’IBM e all’allora suo presidente Watson, sviluppando il primo corpus in formato elettronico, inizialmente con schede perforate e solo successivamente con nastri magnetici.
Era ormai tracciato un percorso che all’inizio era ancora limitato dalle capacità dei primi computer; questi vincoli sono stati oramai superati dall’attuale sviluppo delle capacità di memoria e di calcolo degli elaboratori.
In realtà, poiché l’analisi dei testi si concentra su documenti scritti in italiano o in inglese (i cosiddetti linguaggi naturali), essa si può ascrivere al campo dell’elaborazione del linguaggio naturale, più nota con il termine inglese “Natural Language Processing” (NLP).
Visto lo spazio limitato e gli scopi divulgativi di questo articolo, ci concentreremo sullo spiegare come sia possibile capire, attraverso un algoritmo, se un testo è scritto in modo simile a un altro.
Sarà chiaro al lettore che la complessità di un linguaggio naturale come l’italiano o l’inglese è alta per la presenza di un elevato numero di ambiguità terminologiche, che solo la comprensione del contesto in cui un termine è inserito può risolvere.
Stante questa difficoltà, sono state sviluppate una serie di tecniche per estrarre informazioni in grado di analizzare e caratterizzare questi testi.
L’applicazione di questi algoritmi ha avuto un ulteriore impulso per l’interesse commerciale dei grandi colossi dell’Informatica a trarre informazioni dal gran numero di dati (indicati con lo spesso abusato termine di Big Data) che i social network come Twitter e Facebook accumulano giornalmente.
Viene utilizzato, in questi casi, il termine di “Text Mining”, l’applicazione ai testi del più noto campo del “Data Mining” ovvero di quell’insieme di tecniche che vengono utilizzate per “scavare” fra i dati ed estrarre informazioni utili.
Come anticipato, nel prossimo paragrafo vedremo i modi più semplici per capire se un testo è simile a un altro.
La “distanza” in matematica
Certamente nessuno dei lettori avrebbe dubbi su come rispondere alla domanda: «Come si misura la distanza fra due oggetti su un tavolo?».
Se si conoscono le coordinate di due punti, si potrebbe utilizzare la formula per il calcolo della distanza fra due punti (una banale applicazione del teorema di Pitagora), che in due dimensioni è espressa dalla formula:
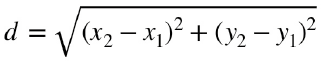
Se invece voi foste dei tassisti della città di Manhattan, sapreste che per andare dal punto A al punto B dovreste seguire la piantina della città fatta di vie che si incontrano idealmente in modo perpendicolare; in questo caso per determinare la distanza bisognerebbe calcolare la lunghezza di una spezzata secondo la seguente relazione (sempre nel caso bidimensionale):
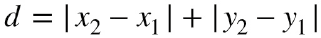
Un altro tipo di misura, che può in qualche modo indicare una vicinanza fra due punti, è chiamata similarità del coseno e consiste nel calcolare il coseno dell’angolo formato fra i due vettori.

Esempio di percorsi che si possono realizzare corrispondenti a quella che viene chiamata “distanza del tassista".
Cosa si dovrebbe fare invece per misurare in modo quantitativo la vicinanza o meno di due testi scritti?
Una risposta, a questo punto forse l’avrete intuita, è quella di trasformare un testo in un vettore, un vettore di parole.
Il vantaggio delle misure che in matematica vengono usate come “distanze” è che sono generalizzabili in uno spazio a n dimensioni, una per ogni parola.
E cosa posso mettere in questo spazio a n dimensioni? Nella versione più semplice, per esempio, posso mettere la frequenza con cui compare quella parola nel testo.
Questa tecnica si chiama in inglese bag of words, ovvero borsa delle parole, perché è un po’ come prendere le parole di un testo e infilarle in una borsa in cui, perdendo memoria dell’ordine e della vicinanza dei vari termini, esse vengono contate.
Se per esempio si dovessero confrontare due testi come: «Andrea mangia il panino» e «Il cane gioca con il bastone» si potrebbe per prima cosa trasformare le frasi in sequenza di parole e considerare la frequenza di ognuna ottenendo:
- Testo1= {“Andrea”: 1, “mangia”:1, “il”:1, “panino”:1}
- Testo2={“il”: 2, “cane”:1, “gioca”:1, “con”:1, “bastone”:1 }
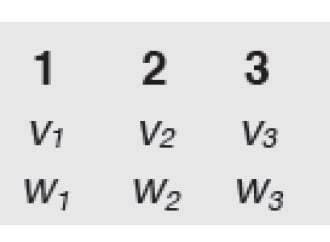
In seguito, si conta il numero n di parole diverse presenti in entrambe le frasi, seguendo un ordine deciso arbitrariamente e si rappresentano i testi come vettori in uno spazio a n dimensioni riportando ordinatamente la frequenza di ciascuna parola. Nel nostro esempio, il numero n è otto; scegliendo l’ordine: mangia, il, gelato, cane, gioca, con, sasso , si ha:
- Testo1 = 1,1,1,1,0,0,0,0
- Testo2 = 0,0,2,0,1,1,1,1
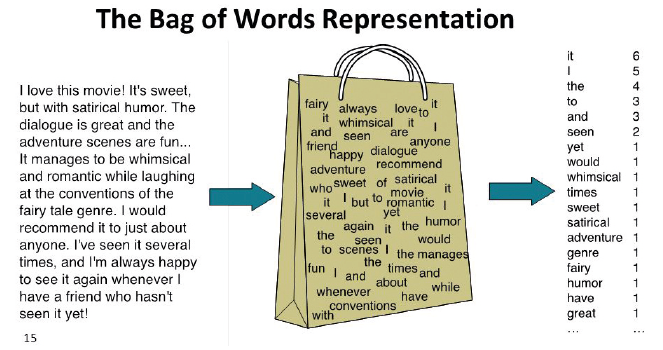
Immagine che rappresenta in modo schematico il funzionamento della “borsa delle parole”.
Ovviamente questa scelta è una approssimazione. L’ordine delle parole conta (e in alcune lingue conta più che in altre), ma spesso nella scienza alcune approssimazioni sono utili, se si è consapevoli delle limitazioni che ne derivano. Ovviamente la matematica offre la possibilità di usare degli strumenti più complessi come, per esempio, i cosiddetti n-grammi, oppure tecniche di compressione o misure di entropia dei testi. In questo caso l’idea è la stessa delle misure di similarità spiegate precedentemente: a testi simili corrisponderanno dei valori di entropia o di compressione vicini fra loro.
Ancora una volta, a prescindere dal metodo utilizzato, sia se si applica qualcuno di quelli brevemente spiegati, sia se si applicano approcci diversi, si scoprirà il valore della matematica nell’aiutare a scoprire plagi e falsi o nell’identificare l’autore di testi pubblicati in modo anonimo.
Note
1) G. K. Zipf, Human Behaviour and the Principle of Least Effort. Addison-Wesley, Reading, MA, 1949.
2) G. U. Yule, A statistical study of vocabulary, Cambridge University Press, Cambridge, 1944
3) Thomas N. Winter, Roberto Busa, S.J., and the Invention of the Machine-Generated Condordance, Digital commons, University of Nebraska.
Per approfondire si veda:
- Mirko Degli Esposti, Riconoscere Gramsci con la matematica, disponibile qui http://www.treccani.it/magazine/lingua_italiana/speciali/attribuzione/Degli_Esposti.html
- C. D. Manning, P. Raghavan, and H. Schütze, Introduction to information retrieval, Cambridge University Press, 2008
- K. Baba, T. Nakatoh, T. Minami, Plagiarism detection using document similarity based on distributed representation, Procedia Computer Science, Volume 111,2017, Pages 382-387, ISSN 1877-0509, https://doi.org/10.1016/j.procs.2017.06.038