
Quasi tutte le maggiori aziende del settore tecnologico, da Google ad Apple passando per Samsung, Huawei e Facebook stanno promuovendo con sempre maggiore intensità un “nuovo prodotto”, che è oramai un protagonista emergente dello sviluppo industriale: l’Intelligenza Artificiale.
Per motivi commerciali, le aziende usano questo termine anche se in molti casi il termine più adeguato sarebbe quello di “Machine Learning” (ML) ovvero, in italiano, “apprendimento automatico”. Con questo termine si intende quel particolare campo dell’Intelligenza Artificiale che riguarda l’insieme degli strumenti sviluppati per permettere a un dispositivo di apprendere e prendere decisioni in autonomia senza essere stato esplicitamente programmato.
Tutti noi utilizziamo e utilizzeremo sempre più dispositivi (per esempio il cellulare, o nel prossimo futuro l’automobile) che riconoscono il nostro volto, rispondono alle nostre domande, ci suggeriscono acquisti da fare, percorsi da seguire, possibili investimenti e amici potenziali.
I veri protagonisti, in realtà, non sono questi gadget tecnologici ma gli algoritmi matematici di apprendimento automatico che ne rendono possibile il funzionamento.
La diffusione di questi algoritmi è costante, visto anche il previsto sviluppo dell’“Internet delle cose”, che metterà in comunicazione i diversi oggetti della nostra vita (dal frigorifero alla bicicletta).
La grande quantità di dati che sempre più ogni utente condividerà nella rete (i famosi Big Data) non potrà che portare a utilizzare algoritmi in grado di svolgere il loro compito in modo autonomo.
«La realtà sta cambiando un algoritmo di apprendimento dopo l’altro», scrive Pedro Domingos, nel suo testo L’algoritmo Definitivo.
Se, infatti, fino a 20-25 anni fa, il Machine Learning era un campo di studi riservato a pochi specialisti, applicato in contesti specifici legati spesso alla ricerca, ora le cose sono cambiate.
I primi algoritmi di ML che sono entrati nella nostra vita quotidiana sono stati quelli che consentivano il riconoscimento dei caratteri dei libri scansionati, il riconoscimento del parlato e soprattutto, visto che è usato in modo massiccio senza averne consapevolezza, quelli che rendono possibile il funzionamento del filtro antispam, che decide se la e-mail arrivata è da considerare spazzatura o meno.
A partire da questi primi programmi di massa, lo sviluppo è stato rapido. Più recentemente è diventato di moda parlare del Deep Learning (una sorta di evoluzione delle reti neurali) e di librerie (Scikit-Learn, TensorFlow) sviluppate da aziende del calibro di Google e fornite liberamente per essere usate da tutti gli sviluppatori di applicazioni.
Sembra ormai evidente che tali tecnologie saranno destinate ad una evoluzione continua.
Il problema è che la stragrande maggioranza degli utilizzatori di questi servizi non hanno consapevolezza del fatto che dietro a tutto questo ci sono degli algoritmi matematici e non hanno idea, neppure a grandi linee, di come possano funzionare.
Nonostante il loro sviluppo e la loro diffusione, gran parte delle persone non ha idea di cosa succede quando si utilizza un algoritmo di apprendimento automatico.
Si potrebbe osservare che è sempre stato così per ogni tecnologia. Oggi usiamo un microonde o un’automobile senza saper spiegare fino in fondo come funzionano.
C’è però una cruciale differenza fra quelle tecnologie e quelle che coinvolgono il Machine Learning. Le seconde, a differenza delle prime, “prendono delle decisioni” autonome, che riguarderanno sempre di più la nostra vita di tutti i giorni.
È quindi importante avere almeno un’idea degli aspetti di base dell’apprendimento automatico, per essere in grado di intuire quello che succede quando usiamo, per continuare a fare degli esempi, assistenti vocali come Siri, Cortana o Alexa.
Riflettere su questa necessità aiuta anche a valutare quali strumenti (dalla scuola, alla divulgazione scientifica) possano essere sviluppati per aiutare a far crescere una cultura diffusa su questi algoritmi.
Il rischio, altrimenti, è quello di alimentare una sorta di “pensiero magico”, che vede il dispositivo come un moderno oracolo in grado di dare risposte e di risolvere problemi; o all’opposto potrebbe considerarlo come la fonte di grandi macchinazioni complottiste. Il recente scandalo legato alla società Cambridge Analityca, che ha avuto una grande eco e suscitato altrettanto stupore, offre una conferma in questo senso.
Del resto, è possibile già ora osservare atteggiamenti molto diversi verso gli algoritmi automatici: alcuni orientati ad un entusiasmo acritico, altri pregiudizialmente negativi, per i quali la perdita dei posti di lavoro dovuta alle macchine “intelligenti” non comporterà anche la creazione di nuovi e diversi posti di lavoro.
Ovviamente ciascuno è libero di formarsi un proprio convincimento e punto di vista, anche perché il settore è in rapido sviluppo e non è semplice prevederne le ricadute sociali ed economiche.
Proprio per aiutare a sviluppare la consapevolezza circa le questioni in gioco, nella seconda parte di questo articolo cercheremo di spiegare come un algoritmo possa prendere delle decisioni in modo autonomo. In altri termini, risponderemo alla domanda: come è possibile che un programma capisca qualcosa di nuovo e prenda delle decisioni?
In realtà non lo fa, almeno nel senso in cui lo facciamo noi.
Per spiegarci meglio, illustriamo il funzionamento di un algoritmo di classificazione tipico del Machine Learning che è stato creato per prendere una decisione come quella di classificare un nuovo fenomeno all’interno di un numero di classi predefinite.
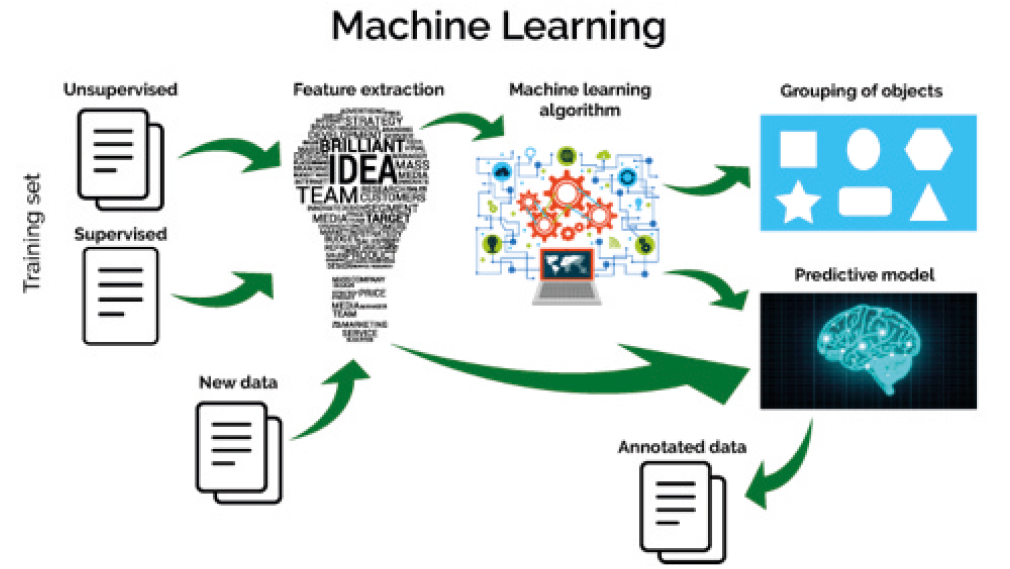
La maggior parte degli algoritmi nel campo del ML sono “supervisionati”: l’algoritmo di apprendimento (learner) utilizza un dataset di allenamento (training dataset). A partire da questi dati, il learner estrapola delle caratteristiche e crea un mondo in uno spazio a n dimensioni in cui in ogni asse è rappresentata una di queste caratteristiche (features).
Se, per esempio, dovessimo riconoscere nelle immagini postate su internet quelle che contengono Babbo Natale, una delle caratteristiche potrebbe essere quella della quantità di rosso nella foto. Ovviamente la cosa non basta perché con questo unico parametro tutte le Ferrari rosso fuoco diventerebbero, per il nostro algoritmo, Babbo Natale.
Quello che si è visto in realtà è che molto spesso funzionano dei parametri matematici molto astratti, che non hanno niente a che fare con quello che noi, con la nostra intelligenza, cercheremmo nelle immagini. Essendo i contesti di utilizzo del ML diversissimi fra loro (suoni, immagini, parole), l’estrarre caratteristiche astratte non strettamente collegate al problema in esame rende questi learners più facilmente adattabili ad applicazioni concrete molto disparate.
Il punto centrale è che in questo spazio a n dimensioni ci si aspetta che, se scegliamo bene le features, tutti i Babbi Natale siano messi da una parte e che, invece, le Ferrari si posizionino insieme con tutte le auto rosse dall’altra.
In altri termini, immaginate che il cielo sia lo spazio dei parametri: in esso compariranno tante nuvole che rappresenteranno i raggruppamenti (cluster) dei dati.
A nuvole diverse, per l’algoritmo corrispondono “cose” classificate come diverse. Ovviamente non è così semplice e spesso, per esempio, le “nuvole” che rappresentano gli oggetti nello spazio dei parametri si sovrappongono, almeno parzialmente, fra loro.
Fondamentale sarà quindi il criterio di scelta e il modo con cui misurare la distanza fra i punti.
Una volta che l’algoritmo, attraverso un serie di dati campione di “allenamento”, è in grado di separare in classi, diventa possibile mostrargli un nuovo oggetto, mai visto prima, e chiedergli di classificarlo. È inoltre possibile creare algoritmi che sulla base dei dati precedenti “imparino” e migliorino le loro capacità decisionali.
La figura 1 rappresenta uno schema tipico di molti algoritmi di Machine Learning. Partendo da una serie di dati iniziali di allenamento (training dataset) che possono essere supervisionati (ovvero un utente li classifica in base al problema da analizzare) o non supervisionati, si estraggono delle caratteristiche (fase di feature extraction). Su queste agiscono algoritmi (diversi in base al contesto di applicazione) che sono in grado di raggruppare gli oggetti che si presentano loro (nell’esempio classifica i quadrati con i quadrati, i triangoli con i triangoli e così via) e/o sono in grado di fare una previsione in base ad un modello elaborato dai dati. I nuovi dati in ingresso saranno quindi interpretati alla luce di quanto appreso in precedenza.
Arthur C. Clarke, scrittore di fantascienza celebre per il suo romanzo “2001: Odissea nello spazio”, affermava: «Ogni tecnologia abbastanza progredita è indistinguibile dalla magia».
Questa affermazione può essere valida per ogni epoca. Sembra però che, oggi più che mai, essa descriva efficacemente sia il rapporto che si instaura tra dispositivo tecnologico e utilizzatore, sia il funzionamento della più avanzata tecnologia odierna cioè quella informatica.
In un celebre racconto di Isaac Asimov si narra di un mondo in cui tutto era stato demandato ai computer, tanto che l’umanità aveva completamente dimenticato come fare i conti più semplici senza avvalersi di un elaboratore elettronico. In questo distopico futuro, il protagonista scopre che è possibile fare questi calcoli a mente, e in questo modo genera grande stupore fra i suoi superiori.
Oggi siamo molto lontani da questi estremi, ma resta vero che l’ignoranza verso il funzionamento di una tecnologia rischia di generare atteggiamenti non basati su dati di fatto, di alimentare “fake news” e di contribuire alla diffusione di un atteggiamento antiscientifico dannoso.
Nel caso di un possibile algoritmo di classificazione supervisionata presentato sopra, abbiamo visto come di “magico” ci sia ben poco, in quanto il suo funzionamento è garantito da procedure e logiche matematiche.
Non possiamo che sperare che questa consapevolezza si diffonda e con essa anche le competenze matematiche che consentono di capire (almeno a grandi linee) gli algoritmi che ci sono dietro.
Per motivi commerciali, le aziende usano questo termine anche se in molti casi il termine più adeguato sarebbe quello di “Machine Learning” (ML) ovvero, in italiano, “apprendimento automatico”. Con questo termine si intende quel particolare campo dell’Intelligenza Artificiale che riguarda l’insieme degli strumenti sviluppati per permettere a un dispositivo di apprendere e prendere decisioni in autonomia senza essere stato esplicitamente programmato.
Tutti noi utilizziamo e utilizzeremo sempre più dispositivi (per esempio il cellulare, o nel prossimo futuro l’automobile) che riconoscono il nostro volto, rispondono alle nostre domande, ci suggeriscono acquisti da fare, percorsi da seguire, possibili investimenti e amici potenziali.
I veri protagonisti, in realtà, non sono questi gadget tecnologici ma gli algoritmi matematici di apprendimento automatico che ne rendono possibile il funzionamento.
La diffusione di questi algoritmi è costante, visto anche il previsto sviluppo dell’“Internet delle cose”, che metterà in comunicazione i diversi oggetti della nostra vita (dal frigorifero alla bicicletta).
La grande quantità di dati che sempre più ogni utente condividerà nella rete (i famosi Big Data) non potrà che portare a utilizzare algoritmi in grado di svolgere il loro compito in modo autonomo.
Algoritmi di apprendimento
«La realtà sta cambiando un algoritmo di apprendimento dopo l’altro», scrive Pedro Domingos, nel suo testo L’algoritmo Definitivo.
Se, infatti, fino a 20-25 anni fa, il Machine Learning era un campo di studi riservato a pochi specialisti, applicato in contesti specifici legati spesso alla ricerca, ora le cose sono cambiate.
I primi algoritmi di ML che sono entrati nella nostra vita quotidiana sono stati quelli che consentivano il riconoscimento dei caratteri dei libri scansionati, il riconoscimento del parlato e soprattutto, visto che è usato in modo massiccio senza averne consapevolezza, quelli che rendono possibile il funzionamento del filtro antispam, che decide se la e-mail arrivata è da considerare spazzatura o meno.
A partire da questi primi programmi di massa, lo sviluppo è stato rapido. Più recentemente è diventato di moda parlare del Deep Learning (una sorta di evoluzione delle reti neurali) e di librerie (Scikit-Learn, TensorFlow) sviluppate da aziende del calibro di Google e fornite liberamente per essere usate da tutti gli sviluppatori di applicazioni.
Sembra ormai evidente che tali tecnologie saranno destinate ad una evoluzione continua.
Il problema è che la stragrande maggioranza degli utilizzatori di questi servizi non hanno consapevolezza del fatto che dietro a tutto questo ci sono degli algoritmi matematici e non hanno idea, neppure a grandi linee, di come possano funzionare.
Nonostante il loro sviluppo e la loro diffusione, gran parte delle persone non ha idea di cosa succede quando si utilizza un algoritmo di apprendimento automatico.
Si potrebbe osservare che è sempre stato così per ogni tecnologia. Oggi usiamo un microonde o un’automobile senza saper spiegare fino in fondo come funzionano.
C’è però una cruciale differenza fra quelle tecnologie e quelle che coinvolgono il Machine Learning. Le seconde, a differenza delle prime, “prendono delle decisioni” autonome, che riguarderanno sempre di più la nostra vita di tutti i giorni.
È quindi importante avere almeno un’idea degli aspetti di base dell’apprendimento automatico, per essere in grado di intuire quello che succede quando usiamo, per continuare a fare degli esempi, assistenti vocali come Siri, Cortana o Alexa.
Riflettere su questa necessità aiuta anche a valutare quali strumenti (dalla scuola, alla divulgazione scientifica) possano essere sviluppati per aiutare a far crescere una cultura diffusa su questi algoritmi.
Il rischio, altrimenti, è quello di alimentare una sorta di “pensiero magico”, che vede il dispositivo come un moderno oracolo in grado di dare risposte e di risolvere problemi; o all’opposto potrebbe considerarlo come la fonte di grandi macchinazioni complottiste. Il recente scandalo legato alla società Cambridge Analityca, che ha avuto una grande eco e suscitato altrettanto stupore, offre una conferma in questo senso.
Del resto, è possibile già ora osservare atteggiamenti molto diversi verso gli algoritmi automatici: alcuni orientati ad un entusiasmo acritico, altri pregiudizialmente negativi, per i quali la perdita dei posti di lavoro dovuta alle macchine “intelligenti” non comporterà anche la creazione di nuovi e diversi posti di lavoro.
Ovviamente ciascuno è libero di formarsi un proprio convincimento e punto di vista, anche perché il settore è in rapido sviluppo e non è semplice prevederne le ricadute sociali ed economiche.
Proprio per aiutare a sviluppare la consapevolezza circa le questioni in gioco, nella seconda parte di questo articolo cercheremo di spiegare come un algoritmo possa prendere delle decisioni in modo autonomo. In altri termini, risponderemo alla domanda: come è possibile che un programma capisca qualcosa di nuovo e prenda delle decisioni?
In realtà non lo fa, almeno nel senso in cui lo facciamo noi.
Per spiegarci meglio, illustriamo il funzionamento di un algoritmo di classificazione tipico del Machine Learning che è stato creato per prendere una decisione come quella di classificare un nuovo fenomeno all’interno di un numero di classi predefinite.
Un esempio di algoritmo di Machine Learning: la classificazione
La maggior parte degli algoritmi nel campo del ML sono “supervisionati”: l’algoritmo di apprendimento (learner) utilizza un dataset di allenamento (training dataset). A partire da questi dati, il learner estrapola delle caratteristiche e crea un mondo in uno spazio a n dimensioni in cui in ogni asse è rappresentata una di queste caratteristiche (features).
Se, per esempio, dovessimo riconoscere nelle immagini postate su internet quelle che contengono Babbo Natale, una delle caratteristiche potrebbe essere quella della quantità di rosso nella foto. Ovviamente la cosa non basta perché con questo unico parametro tutte le Ferrari rosso fuoco diventerebbero, per il nostro algoritmo, Babbo Natale.
Quello che si è visto in realtà è che molto spesso funzionano dei parametri matematici molto astratti, che non hanno niente a che fare con quello che noi, con la nostra intelligenza, cercheremmo nelle immagini. Essendo i contesti di utilizzo del ML diversissimi fra loro (suoni, immagini, parole), l’estrarre caratteristiche astratte non strettamente collegate al problema in esame rende questi learners più facilmente adattabili ad applicazioni concrete molto disparate.
Il punto centrale è che in questo spazio a n dimensioni ci si aspetta che, se scegliamo bene le features, tutti i Babbi Natale siano messi da una parte e che, invece, le Ferrari si posizionino insieme con tutte le auto rosse dall’altra.
In altri termini, immaginate che il cielo sia lo spazio dei parametri: in esso compariranno tante nuvole che rappresenteranno i raggruppamenti (cluster) dei dati.
A nuvole diverse, per l’algoritmo corrispondono “cose” classificate come diverse. Ovviamente non è così semplice e spesso, per esempio, le “nuvole” che rappresentano gli oggetti nello spazio dei parametri si sovrappongono, almeno parzialmente, fra loro.
Fondamentale sarà quindi il criterio di scelta e il modo con cui misurare la distanza fra i punti.
Una volta che l’algoritmo, attraverso un serie di dati campione di “allenamento”, è in grado di separare in classi, diventa possibile mostrargli un nuovo oggetto, mai visto prima, e chiedergli di classificarlo. È inoltre possibile creare algoritmi che sulla base dei dati precedenti “imparino” e migliorino le loro capacità decisionali.
La figura 1 rappresenta uno schema tipico di molti algoritmi di Machine Learning. Partendo da una serie di dati iniziali di allenamento (training dataset) che possono essere supervisionati (ovvero un utente li classifica in base al problema da analizzare) o non supervisionati, si estraggono delle caratteristiche (fase di feature extraction). Su queste agiscono algoritmi (diversi in base al contesto di applicazione) che sono in grado di raggruppare gli oggetti che si presentano loro (nell’esempio classifica i quadrati con i quadrati, i triangoli con i triangoli e così via) e/o sono in grado di fare una previsione in base ad un modello elaborato dai dati. I nuovi dati in ingresso saranno quindi interpretati alla luce di quanto appreso in precedenza.
Prevenire ed evitare la superstizione
Arthur C. Clarke, scrittore di fantascienza celebre per il suo romanzo “2001: Odissea nello spazio”, affermava: «Ogni tecnologia abbastanza progredita è indistinguibile dalla magia».
Questa affermazione può essere valida per ogni epoca. Sembra però che, oggi più che mai, essa descriva efficacemente sia il rapporto che si instaura tra dispositivo tecnologico e utilizzatore, sia il funzionamento della più avanzata tecnologia odierna cioè quella informatica.
In un celebre racconto di Isaac Asimov si narra di un mondo in cui tutto era stato demandato ai computer, tanto che l’umanità aveva completamente dimenticato come fare i conti più semplici senza avvalersi di un elaboratore elettronico. In questo distopico futuro, il protagonista scopre che è possibile fare questi calcoli a mente, e in questo modo genera grande stupore fra i suoi superiori.
Oggi siamo molto lontani da questi estremi, ma resta vero che l’ignoranza verso il funzionamento di una tecnologia rischia di generare atteggiamenti non basati su dati di fatto, di alimentare “fake news” e di contribuire alla diffusione di un atteggiamento antiscientifico dannoso.
Nel caso di un possibile algoritmo di classificazione supervisionata presentato sopra, abbiamo visto come di “magico” ci sia ben poco, in quanto il suo funzionamento è garantito da procedure e logiche matematiche.
Non possiamo che sperare che questa consapevolezza si diffonda e con essa anche le competenze matematiche che consentono di capire (almeno a grandi linee) gli algoritmi che ci sono dietro.
Riferimenti bibliografici
- P. Domingos, L'algoritmo definitivo. La macchina che impara da sola e il futuro del nostro mondo, Bollati Boringhieri 2016
- D. Cardon, Che cosa sognano gli algoritmi. Le nostre vite al tempo dei big data, Mondadori 2016.
- F. Di Pietro, Tié! Una indagine sulla superstizione nella cultura materiale, disponibile qui: https://bit.ly/2ywkieV
- I. Asimov, Nove volte sette in Racconti matematici, Einaudi Torino 2006.









