
Definire un criterio generale per stabilire se il risultato di uno studio scientifico sia statisticamente significativo non è per niente banale. Che si tratti della valutazione di efficacia di un nuovo farmaco, della relazione tra percentuale di gas serra nell’atmosfera e temperatura globale della Terra o magari del successo in determinate discipline degli appartenenti ai vari segni zodiacali, la questione è molto delicata.
Su Query ci siamo occupati spesso di come questo problema venga affrontato nella letteratura scientifica e di come il criterio più diffuso per misurare la significatività statistica sia l’uso del cosiddetto “p-value” (in italiano, “valore p”)[1].
Il punto di partenza è che la correlazione statistica tra una variabile x e un effetto y non implica necessariamente una relazione di causalità tra x e y. Se, per esempio, in uno studio clinico il gruppo che riceve il principio attivo Rilassina contro l’ipertensione risulta avere valori di pressione arteriosa più bassi di quello che riceve il placebo, non posso essere sicuro che la causa sia proprio il farmaco: potrebbe essere semplicemente un caso. Per questa ragione si capovolge il ragionamento: partiamo dall’ipotesi che la variabile x non abbia alcun effetto (“ipotesi nulla”) e calcoliamo in base ai risultati dello studio la probabilità p che l’effetto si manifesti ugualmente per puro caso.
Se questa probabilità è molto piccola (per esempio sotto il cinque per cento) è ragionevole pensare che la variabile x abbia davvero un effetto, per esempio appunto che la Rilassina sia efficace contro l’ipertensione.
A partire dallo stesso inventore del p-value, il grande biologo e statistico inglese Ronald Fisher, gli scienziati sanno benissimo che il p-value è soltanto una delle tecniche che si possono usare per misurare l’attendibilità di un risultato e che la soglia di 0,05 è totalmente arbitraria e non ha alcuna ragione particolare per essere preferita a un’altra. Tuttavia, l’uso del p-value con una soglia di significatività pari a 0,05 è finito per diventare quasi uno standard, soprattutto nelle scienze sociali e biomediche, con alcune conseguenze non volute.
 Qualche anno fa su questa rubrica abbiamo parlato dell’“effetto declino”: la tendenza di numerosi risultati scientifici a essere replicati in misura inferiore, o addirittura a non essere replicati per nulla, negli studi successivi[2].
Qualche anno fa su questa rubrica abbiamo parlato dell’“effetto declino”: la tendenza di numerosi risultati scientifici a essere replicati in misura inferiore, o addirittura a non essere replicati per nulla, negli studi successivi[2].
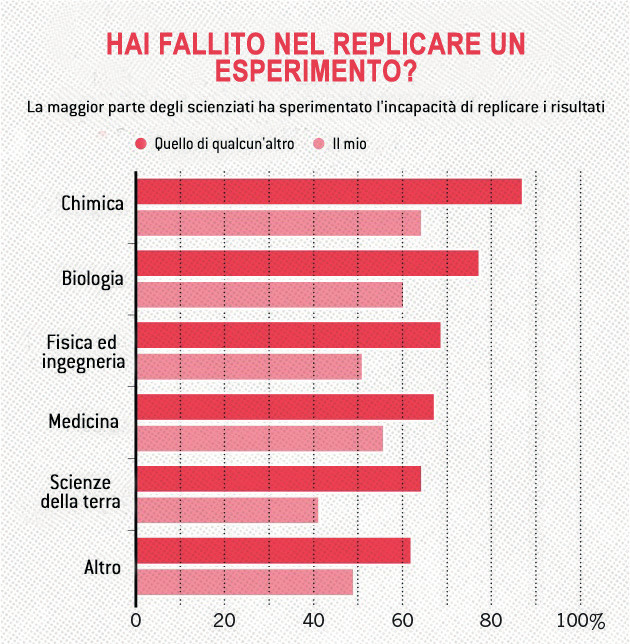
Negli ultimi anni la preoccupazione per questo fenomeno è aumentata tra gli scienziati, che sono arrivati a parlare apertamente di “crisi della riproducibilità”[3]. Nel 2016, un sondaggio di Nature tra 1576 ricercatori ha mostrato che più del 70% di loro non era riuscito almeno una volta a riprodurre un esperimento di un altro scienziato[4]. La difficile riproducibilità degli studi scientifici è considerata uno dei fattori che fanno perdere credibilità alla scienza, perché alimenta i dubbi sull’attendibilità e sull’integrità della comunità accademica.
Le cause della crisi di riproducibilità sono molteplici e ne parleremo in uno dei prossimi articoli: qui ci concentriamo soltanto sull’uso improprio del p-value.
Il problema non è soltanto quello di attribuire troppa importanza al valore di p, trascurando altri strumenti che permettono di giudicare criticamente il valore di un risultato scientifico, ma anche quello di manipolare i risultati attraverso la cosiddetta tecnica del “phacking”: scegliendo opportunamente i parametri dell’esperimento o dell’analisi statistica, si può cercare di abbassare il p-value fino ad arrivare al valore desiderato. Per esempio, si possono presentare come ipotesi fatte fin dall’inizio correlazioni che in realtà sono state scoperte solo nel corso dell’esperimento, oppure si può scartare una parte del campione con criteri che appaiono ragionevoli, ma che servono ad accentuare l’effetto cercato.
Per questa ragione la tendenza a incentrare l’analisi statistica sul solo p-value è stata molto contestata. Nel 2015 la rivista Basic and Applied Social Psychology ha annunciato che non avrebbe più accettato studi basati sul p-value[5]. Nel 2016 l’Associazione Statistica Americana ha rilasciato una dichiarazione ufficiale che metteva in guardia contro il cattivo uso del p-value[6] e sempre nel 2016 un gruppo di ricercatori olandesi ha pubblicato uno studio che evidenziava ben 34 modi diversi attraverso i quali ricercatori poco scrupolosi potevano “addomesticare” il valore di p[7].
 La discussione è proseguita nel 2017, quando un gruppo di 72 scienziati ha proposto ufficialmente di abbassare la soglia standard del p-value per le scienze sociali e biomediche da 0,05 a 0,005, cioè dal cinque per cento al cinque per mille[8]. Altre discipline, come la fisica delle particelle, sono abituate da tempo a usare soglie di significatività molto più basse. L’articolo fornisce per questa proposta una complessa giustificazione matematica, che mostra, tra le altre cose, come passare da 0,05 a 0,005 permetterebbe di parlare di prova sostanziale anche da un punto di vista bayesiano[9]. Tra gli autori della proposta ci sono nomi noti come quello di John A. Ioannidis, attualmente uno degli scienziati più autorevoli nella critica alla pratica scientifica e più impegnati nel combattere la crisi di credibilità della scienza.
La discussione è proseguita nel 2017, quando un gruppo di 72 scienziati ha proposto ufficialmente di abbassare la soglia standard del p-value per le scienze sociali e biomediche da 0,05 a 0,005, cioè dal cinque per cento al cinque per mille[8]. Altre discipline, come la fisica delle particelle, sono abituate da tempo a usare soglie di significatività molto più basse. L’articolo fornisce per questa proposta una complessa giustificazione matematica, che mostra, tra le altre cose, come passare da 0,05 a 0,005 permetterebbe di parlare di prova sostanziale anche da un punto di vista bayesiano[9]. Tra gli autori della proposta ci sono nomi noti come quello di John A. Ioannidis, attualmente uno degli scienziati più autorevoli nella critica alla pratica scientifica e più impegnati nel combattere la crisi di credibilità della scienza.
L’obiettivo è migliorare la riproducibilità degli studi scientifici, riducendo il numero di falsi positivi (errori di tipo I). Per definizione, la scelta di una soglia del 5% significa che accettiamo di avere una probabilità di errore di tipo I del 5%. Quando abbiamo un solo esperimento che dà un risultato positivo, non possiamo sapere se l’effetto esiste veramente o se rientriamo nel 5% di casi in cui il test dà casualmente un risultato positivo anche se il fenomeno non esiste. Soltanto ripetendo più volte lo studio, riusciremo a capire se il risultato positivo era genuino oppure no.
Abbassare la soglia al cinque per mille ridurrebbe molto la probabilità di errori di tipo I, quindi i risultati statisticamente significativi sarebbero più rari, ma più affidabili e più riproducibili. Tuttavia, questa operazione non sarebbe indolore, perché aumenterebbe proporzionalmente il numero di falsi negativi (errori di tipo II). Il rischio di un’asticella troppo alta sarebbe quello di ignorare risultati potenzialmente importanti e rallentare il progresso scientifico.
Anticipando questa obiezione, i 72 scienziati hanno proposto di continuare a pubblicare anche i risultati con un p-value compreso tra 0,005 e 0,05, chiamandoli però “suggestivi” anziché “significativi”. Inoltre, il criterio p< 0,005 si applicherebbe solo alle nuove scoperte, mentre la soglia potrebbe rimanere 0,05 per gli studi che tentano di replicare risultati precedenti.
 La proposta è stata accolta con favore da vari scienziati, tra i quali si può citare il neurologo Steven Novella[10], componente del CSI (l’analogo americano del CICAP), esperto di medicine alternative e coautore del sito sciencebasedmedicine.org (“medicina basata sulla scienza”).
La proposta è stata accolta con favore da vari scienziati, tra i quali si può citare il neurologo Steven Novella[10], componente del CSI (l’analogo americano del CICAP), esperto di medicine alternative e coautore del sito sciencebasedmedicine.org (“medicina basata sulla scienza”).
Tanto Ioannidis quanto Novella sottolineano che la significatività statistica da sola non permette di giudicare il valore di un esperimento e che deve essere combinata con altri strumenti come la misura della dimensione dell’effetto e l’analisi bayesiana. In parole povere, non dovrei chiedermi soltanto se il risultato è statisticamente significativo, ma anche quanto è grande l’effetto rispetto alla grandezza che sto misurando (per esempio, se la Rilassina mi abbassa la pressione diastolica da 100 a 80 mm Hg e mi risolve il problema dell’ipertensione o magari soltanto da 100 a 98 e quindi non ha alcuna utilità clinica). Inoltre, dovrei chiedermi quanto è diventata più probabile la mia ipotesi alla luce dei miei dati sperimentali, magari confrontandola con ipotesi alternative.
Tuttavia, Ioannidis e Novella concordano sul fatto che in questo momento il problema più grave sia la proliferazione dei falsi positivi e, conseguentemente, la scarsa riproducibilità dei risultati: abbassare la soglia del p-value, argomentano, non risolverà tutti i problemi ma è una misura che va nella giusta direzione.
Secondo Stuart Vyse, psicologo e anche lui socio del CSI, è difficile che la proposta di Ioannidis e colleghi entri in uso, sia perché la preoccupazione di introdurre troppi falsi negativi finirà per prevalere, sia perché questa soluzione non andrebbe a toccare le dinamiche della letteratura scientifica.
Per poter fare carriera i ricercatori sono obbligati a pubblicare molti studi, secondo la dinamica del publish or perish (pubblica o muori) e i loro articoli sono una ricca fonte di profitti per l’editoria scientifica[11]. Il giro d’affari delle pubblicazioni accademiche, secondo un’inchiesta del Guardian, è di 19 miliardi di dollari l’anno, paragonabile a quello dell’industria discografica e cinematografica, ma con una redditività molto maggiore: nel 2010 il ramo editoriale di Elsevier (il maggior gruppo editoriale mondiale in ambito medico e scientifico) dichiarò un utile del 36% del fatturato, superiore a quello di giganti come Apple, Google e Amazon. Gli interessi economici nella letteratura scientifica sono un ulteriore tema di discussione di fondamentale importanza al quale dedicheremo spazio in futuro[12].
Per il momento ci limitiamo a constatare come sia indispensabile diffondere tra i ricercatori una più solida cultura statistica, che permetta di conoscere meglio le limitazioni nell’uso del p-value e le caratteristiche degli altri strumenti di analisi dei risultati, al fine di rendere più accurata la metodologia degli studi scientifici. Questo aspetto è particolarmente importante per gli studi condotti da gruppi ristretti di ricercatori che non comprendono esperti in statistica.
Ancora una volta, l’idea di un “metodo scientifico” universale e immutabile è molto distante dalla realtà. La ricerca scientifica continua a evolversi: non soltanto le conoscenze scientifiche vengono continuamente messe in discussione, ma anche i processi attraverso cui vengono accertate e diffuse cambiano nel tempo, sotto l’azione di diversi fattori e con l’aiuto di diverse discipline complementari.
Su Query ci siamo occupati spesso di come questo problema venga affrontato nella letteratura scientifica e di come il criterio più diffuso per misurare la significatività statistica sia l’uso del cosiddetto “p-value” (in italiano, “valore p”)[1].
Il punto di partenza è che la correlazione statistica tra una variabile x e un effetto y non implica necessariamente una relazione di causalità tra x e y. Se, per esempio, in uno studio clinico il gruppo che riceve il principio attivo Rilassina contro l’ipertensione risulta avere valori di pressione arteriosa più bassi di quello che riceve il placebo, non posso essere sicuro che la causa sia proprio il farmaco: potrebbe essere semplicemente un caso. Per questa ragione si capovolge il ragionamento: partiamo dall’ipotesi che la variabile x non abbia alcun effetto (“ipotesi nulla”) e calcoliamo in base ai risultati dello studio la probabilità p che l’effetto si manifesti ugualmente per puro caso.
Se questa probabilità è molto piccola (per esempio sotto il cinque per cento) è ragionevole pensare che la variabile x abbia davvero un effetto, per esempio appunto che la Rilassina sia efficace contro l’ipertensione.
A partire dallo stesso inventore del p-value, il grande biologo e statistico inglese Ronald Fisher, gli scienziati sanno benissimo che il p-value è soltanto una delle tecniche che si possono usare per misurare l’attendibilità di un risultato e che la soglia di 0,05 è totalmente arbitraria e non ha alcuna ragione particolare per essere preferita a un’altra. Tuttavia, l’uso del p-value con una soglia di significatività pari a 0,05 è finito per diventare quasi uno standard, soprattutto nelle scienze sociali e biomediche, con alcune conseguenze non volute.
Negli ultimi anni la preoccupazione per questo fenomeno è aumentata tra gli scienziati, che sono arrivati a parlare apertamente di “crisi della riproducibilità”[3]. Nel 2016, un sondaggio di Nature tra 1576 ricercatori ha mostrato che più del 70% di loro non era riuscito almeno una volta a riprodurre un esperimento di un altro scienziato[4]. La difficile riproducibilità degli studi scientifici è considerata uno dei fattori che fanno perdere credibilità alla scienza, perché alimenta i dubbi sull’attendibilità e sull’integrità della comunità accademica.
Le cause della crisi di riproducibilità sono molteplici e ne parleremo in uno dei prossimi articoli: qui ci concentriamo soltanto sull’uso improprio del p-value.
Il problema non è soltanto quello di attribuire troppa importanza al valore di p, trascurando altri strumenti che permettono di giudicare criticamente il valore di un risultato scientifico, ma anche quello di manipolare i risultati attraverso la cosiddetta tecnica del “phacking”: scegliendo opportunamente i parametri dell’esperimento o dell’analisi statistica, si può cercare di abbassare il p-value fino ad arrivare al valore desiderato. Per esempio, si possono presentare come ipotesi fatte fin dall’inizio correlazioni che in realtà sono state scoperte solo nel corso dell’esperimento, oppure si può scartare una parte del campione con criteri che appaiono ragionevoli, ma che servono ad accentuare l’effetto cercato.
Per questa ragione la tendenza a incentrare l’analisi statistica sul solo p-value è stata molto contestata. Nel 2015 la rivista Basic and Applied Social Psychology ha annunciato che non avrebbe più accettato studi basati sul p-value[5]. Nel 2016 l’Associazione Statistica Americana ha rilasciato una dichiarazione ufficiale che metteva in guardia contro il cattivo uso del p-value[6] e sempre nel 2016 un gruppo di ricercatori olandesi ha pubblicato uno studio che evidenziava ben 34 modi diversi attraverso i quali ricercatori poco scrupolosi potevano “addomesticare” il valore di p[7].
L’obiettivo è migliorare la riproducibilità degli studi scientifici, riducendo il numero di falsi positivi (errori di tipo I). Per definizione, la scelta di una soglia del 5% significa che accettiamo di avere una probabilità di errore di tipo I del 5%. Quando abbiamo un solo esperimento che dà un risultato positivo, non possiamo sapere se l’effetto esiste veramente o se rientriamo nel 5% di casi in cui il test dà casualmente un risultato positivo anche se il fenomeno non esiste. Soltanto ripetendo più volte lo studio, riusciremo a capire se il risultato positivo era genuino oppure no.
Abbassare la soglia al cinque per mille ridurrebbe molto la probabilità di errori di tipo I, quindi i risultati statisticamente significativi sarebbero più rari, ma più affidabili e più riproducibili. Tuttavia, questa operazione non sarebbe indolore, perché aumenterebbe proporzionalmente il numero di falsi negativi (errori di tipo II). Il rischio di un’asticella troppo alta sarebbe quello di ignorare risultati potenzialmente importanti e rallentare il progresso scientifico.
Anticipando questa obiezione, i 72 scienziati hanno proposto di continuare a pubblicare anche i risultati con un p-value compreso tra 0,005 e 0,05, chiamandoli però “suggestivi” anziché “significativi”. Inoltre, il criterio p< 0,005 si applicherebbe solo alle nuove scoperte, mentre la soglia potrebbe rimanere 0,05 per gli studi che tentano di replicare risultati precedenti.
Tanto Ioannidis quanto Novella sottolineano che la significatività statistica da sola non permette di giudicare il valore di un esperimento e che deve essere combinata con altri strumenti come la misura della dimensione dell’effetto e l’analisi bayesiana. In parole povere, non dovrei chiedermi soltanto se il risultato è statisticamente significativo, ma anche quanto è grande l’effetto rispetto alla grandezza che sto misurando (per esempio, se la Rilassina mi abbassa la pressione diastolica da 100 a 80 mm Hg e mi risolve il problema dell’ipertensione o magari soltanto da 100 a 98 e quindi non ha alcuna utilità clinica). Inoltre, dovrei chiedermi quanto è diventata più probabile la mia ipotesi alla luce dei miei dati sperimentali, magari confrontandola con ipotesi alternative.
Tuttavia, Ioannidis e Novella concordano sul fatto che in questo momento il problema più grave sia la proliferazione dei falsi positivi e, conseguentemente, la scarsa riproducibilità dei risultati: abbassare la soglia del p-value, argomentano, non risolverà tutti i problemi ma è una misura che va nella giusta direzione.
Secondo Stuart Vyse, psicologo e anche lui socio del CSI, è difficile che la proposta di Ioannidis e colleghi entri in uso, sia perché la preoccupazione di introdurre troppi falsi negativi finirà per prevalere, sia perché questa soluzione non andrebbe a toccare le dinamiche della letteratura scientifica.
Per poter fare carriera i ricercatori sono obbligati a pubblicare molti studi, secondo la dinamica del publish or perish (pubblica o muori) e i loro articoli sono una ricca fonte di profitti per l’editoria scientifica[11]. Il giro d’affari delle pubblicazioni accademiche, secondo un’inchiesta del Guardian, è di 19 miliardi di dollari l’anno, paragonabile a quello dell’industria discografica e cinematografica, ma con una redditività molto maggiore: nel 2010 il ramo editoriale di Elsevier (il maggior gruppo editoriale mondiale in ambito medico e scientifico) dichiarò un utile del 36% del fatturato, superiore a quello di giganti come Apple, Google e Amazon. Gli interessi economici nella letteratura scientifica sono un ulteriore tema di discussione di fondamentale importanza al quale dedicheremo spazio in futuro[12].
Per il momento ci limitiamo a constatare come sia indispensabile diffondere tra i ricercatori una più solida cultura statistica, che permetta di conoscere meglio le limitazioni nell’uso del p-value e le caratteristiche degli altri strumenti di analisi dei risultati, al fine di rendere più accurata la metodologia degli studi scientifici. Questo aspetto è particolarmente importante per gli studi condotti da gruppi ristretti di ricercatori che non comprendono esperti in statistica.
Ancora una volta, l’idea di un “metodo scientifico” universale e immutabile è molto distante dalla realtà. La ricerca scientifica continua a evolversi: non soltanto le conoscenze scientifiche vengono continuamente messe in discussione, ma anche i processi attraverso cui vengono accertate e diffuse cambiano nel tempo, sotto l’azione di diversi fattori e con l’aiuto di diverse discipline complementari.
Note
1) Vedere per esempio: Stefano Bagnasco, “Statisticamente significativo”, in Query n. 1, primavera 2010, Stefano Bagnasco “Sensibile o specifico?”, in 115!Query n. 15, autunno 2013.
2) Andrea Ferrero, “L’effetto declino: quando i fenomeni scompaiono”, in Query n. 7, autunno 2011.
3) “Challenges in irreproducible research” (2018, July 6). Nature Special, consultato in data 4 ottobre 2018 da https://go.nature.com/2A6hFzw .
4) Baker, M. (2016, May 25). 1,500 scientists lift the lid on reproducibility: Survey sheds light on the ‘crisis’ rocking research. Nature. Consultato in data 4 ottobre 2018, da https://go.nature.com/2xPzT8n .
6) American Statistical Association Releases Statement On Statistical Significance And P-Values. (2016, March 7). Consultato in data 4 ottobre 2018, da https://bit.ly/2mw2mXF .
7) Wicherts, J. M., Veldkamp, C. L., Augusteijn, H. E., Bakker, M., Van Aert, R., & Van Assen, M. A. (2016). Degrees of freedom in planning, running, analyzing, and reporting psychological studies: A checklist to avoid p-hacking. Frontiers in Psychology, 7, 1832.
8) Benjamin, D. J., Berger, J. O., Johannesson, M., Nosek, B. A., Wagenmakers, E. J., Berk, R., ... &Cesarini, D. (2018). Redefine statistical significance. Nature Human Behaviour, 2(1), 6.
9) Andrea Ferrero, “L’onere della prova: di chi è?”, in Query n. 15, autunno 2013.
10) Novella, S. (2017, August 2). “0.05 or 0.005? P-value Wars Continue”. Science- Based Medicine. Consultato in data 4 ottobre 2018, da https://bit.ly/2A5tFkF .
11) Stuart Vyse, “Moving Science’s Statistical Goalposts”, Skeptical Inquirer, Vol. 41, No. 6, November/December 2017.
12) Buranyi, S. (2017, June 27). “Is the staggeringly profitable business of scientific publishing bad for science?”. The Guardian. Consultato in data 4 ottobre 2018, da https://bit.ly/2teqjJf













