In un celebre articolo del 1977 di Bradley Efron e Carl Morris,[1] si trova quella che, probabilmente, è una delle migliori spiegazioni del sorprendente paradosso statistico di Stein. Consigliamo fortemente ai lettori di recuperare l’articolo, ottimo esempio di divulgazione scientifica. Il primo autore dell’articolo ha vinto il Premio Samuel S. Wilks, assegnato dall’American Statistical Association per lavori particolarmente validi nel campo della statistica e, fra gli altri meriti, è l’ideatore del metodo bootstrap, nota tecnica statistica di ricampionamento; il secondo autore è stato allievo proprio di Charles Stein.
Nelle pagine che seguono illustreremo il paradosso, prendendo ampiamente spunto dal lavoro appena citato, mostrando in maniera sintetica questo fenomeno, che dà risultati controintuitivi sotto molto aspetti.
Iniziamo con il dire che, se dovessimo pensare ai due processi più utili alla base della statistica, probabilmente citeremmo il contare gli eventi e il calcolarne la media.
Nella mente di ogni persona che abbia frequentato una qualunque scuola italiana è ben chiara l’idea del calcolo della media dei voti, specie se a fine anno si era in dubbio sul voto finale.
Anche solo in modo intuitivo, tutti capiscono che uno dei modi migliori per decidere il voto finale è proprio quello di calcolarne la media (senza ovviamente tenere in considerazione che il processo di valutazione di un docente non si limita a un asettico calcolo della media dei voti, ma questa è un’altra storia); anche in Fisica si insegna che, dopo aver fatto delle misure ripetute di una grandezza, il miglior modo per stimare il valore vero, inconoscibile, della grandezza in esame è quello di calcolarne la media. A costruire questa forma mentis alla base della scienza e dell’abitudine comune hanno contribuito secoli di riflessioni da parte di scienziati del calibro di Gauss e Legendre.
In questa linea di pensiero si colloca il paradosso di Stein che, come dice il nome, genera un fenomeno che contraddice l’idea della media come miglior stimatore di una grandezza.
L’esempio utilizzato da Efron e Morris per spiegare il tutto è particolarmente chiaro per la sua semplicità: parliamo di punteggi dei giocatori di baseball.
Noto l’estremo interesse degli statunitensi per le statistiche nello sport, in particolare nel baseball, Efron e Morris nell’articolo sfruttano proprio i dati disponibili all’epoca. Scrivono: «Un giocatore di baseball che faccia 7 punti su 20 battute negli incontri di un campionato, avrà una media di battuta di 0,35. Nel calcolare questa statistica, facciamo una valutazione dell’effettiva abilità del giocatore nella battuta, in termini di media dei suoi successi» (ovvero 7/20 che fa appunto 0,35).
Se però andiamo a prendere in considerazione tre o più giocatori e cerchiamo di predire la media di battute per ciascuno di essi in futuro, ci accorgiamo che esiste una procedura migliore dell’estrapolazione delle medie di battuta separate. 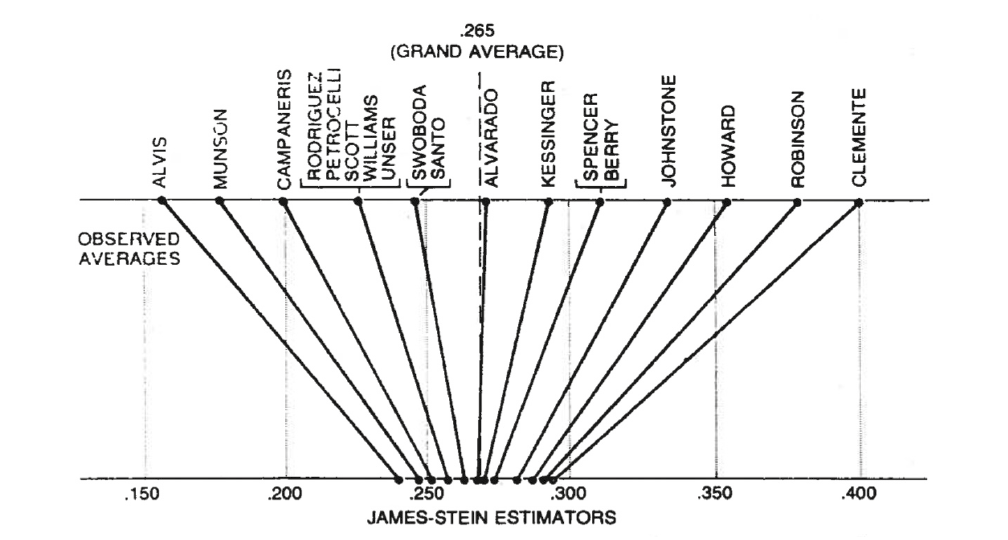
È necessario però prima specificare cosa si intenda per migliore: in questo caso, considereremo come criterio di scelta quello dell’errore quadratico medio, ovvero la discrepanza media fra i valori dei dati osservati e i valori stimati; un risultato sarà tanto migliore quanto più renderà piccolo questo valore.
Torniamo all’esempio del baseball e consideriamo le medie di battuta di 18 giocatori di prima divisione, calcolate dopo le prime 45 battute. La media in questo caso è definita come il numero di volte in cui un giocatore è riuscito a battere diviso per il totale; indichiamo ciascuna di queste 18 medie con la lettera y. A questo punto calcoliamo la media tra le medie di questi valori e la indichiamo con y, termine che Bradley ed Efron battezzano grande media.
Il paradosso di Stein ci dice che c’è un modo migliore dell’usare la media dei singoli giocatori per prevedere la media battute a fine campionato, e per farlo si utilizza quello che viene chiamato stimatore di James-Stein. Per ogni giocatore, tale stimatore assume il seguente valore: z = y + c(y-y).
La quantità (y-y) non è altro che la differenza fra la media del singolo giocatore e quella di tutti. Nella sostanza, la quantità z differisce dalla grande media del termine (y-y) moltiplicato per un fattore c, noto in inglese come shrinkage ovvero restringimento/contrazione.
Non entriamo nel dettaglio del calcolo per la determinazione di c, ma assumiamo per semplicità che corrisponda a un determinato valore sempre minore di uno. Nell’esempio proposto da Efron e Morris lo shrinkage vale 0,212 mentre la grande media vale 0,265.
A questo punto ci chiediamo rispetto a cosa poter confrontare i valori ottenuti da questo stimatore. Infatti, per farlo con precisione dovremmo conoscere la vera abilità di battuta di ogni giocatore, quantità che però non è osservabile direttamente. Non c’è da scoraggiarsi, possiamo fare l’ipotesi di usare tutte le rimanenti partite della stagione di baseball, che sono una quantità di osservazioni di gran lunga superiore rispetto a quelle delle prime 45 battute. Utilizzando questi dati, si calcola che lo stimatore di James-Stein è il migliore, nel senso che produce un errore quadratico medio più piccolo. La media non è il modo migliore per descrivere una grandezza!
Adesso aggiungiamo un ulteriore aspetto che renderà il paradosso ancora più bizzarro. Riutilizziamo l’esempio del baseball tratto dall’articolo: immaginiamo di essere negli anni Settanta e di voler stimare la percentuale di automobili straniere a Chicago. Prendendo un campione casuale di automobili osserviamo che solo 9 delle 45 osservate sono di fabbricazione estera, quindi possiamo stimare il numero tramite la media, 9/45 del totale. Se però immaginiamo di avere a disposizione i dati precedenti del baseball si possono associare i due problemi, un po’ come se la percentuale di auto straniere fosse un diciannovesimo giocatore di baseball, per calcolare lo stimatore di James-Stein e ottenere una stima migliore. Nel teorema di Stein non c’è nulla che richieda un legame fra i vari problemi, quindi il passaggio è legittimo, anche se ha sollevato critiche di diverso tipo; comunque, converrete che questo fatto è decisamente poco intuitivo.
Nelle pagine che seguono illustreremo il paradosso, prendendo ampiamente spunto dal lavoro appena citato, mostrando in maniera sintetica questo fenomeno, che dà risultati controintuitivi sotto molto aspetti.
Iniziamo con il dire che, se dovessimo pensare ai due processi più utili alla base della statistica, probabilmente citeremmo il contare gli eventi e il calcolarne la media.
Nella mente di ogni persona che abbia frequentato una qualunque scuola italiana è ben chiara l’idea del calcolo della media dei voti, specie se a fine anno si era in dubbio sul voto finale.
Anche solo in modo intuitivo, tutti capiscono che uno dei modi migliori per decidere il voto finale è proprio quello di calcolarne la media (senza ovviamente tenere in considerazione che il processo di valutazione di un docente non si limita a un asettico calcolo della media dei voti, ma questa è un’altra storia); anche in Fisica si insegna che, dopo aver fatto delle misure ripetute di una grandezza, il miglior modo per stimare il valore vero, inconoscibile, della grandezza in esame è quello di calcolarne la media. A costruire questa forma mentis alla base della scienza e dell’abitudine comune hanno contribuito secoli di riflessioni da parte di scienziati del calibro di Gauss e Legendre.
In questa linea di pensiero si colloca il paradosso di Stein che, come dice il nome, genera un fenomeno che contraddice l’idea della media come miglior stimatore di una grandezza.
L’esempio utilizzato da Efron e Morris per spiegare il tutto è particolarmente chiaro per la sua semplicità: parliamo di punteggi dei giocatori di baseball.
Noto l’estremo interesse degli statunitensi per le statistiche nello sport, in particolare nel baseball, Efron e Morris nell’articolo sfruttano proprio i dati disponibili all’epoca. Scrivono: «Un giocatore di baseball che faccia 7 punti su 20 battute negli incontri di un campionato, avrà una media di battuta di 0,35. Nel calcolare questa statistica, facciamo una valutazione dell’effettiva abilità del giocatore nella battuta, in termini di media dei suoi successi» (ovvero 7/20 che fa appunto 0,35).
Se però andiamo a prendere in considerazione tre o più giocatori e cerchiamo di predire la media di battute per ciascuno di essi in futuro, ci accorgiamo che esiste una procedura migliore dell’estrapolazione delle medie di battuta separate.
Immagine tratta dall’articolo di Efron e Morris che illustra l’idea d’uso dello stimatore shrinkage
È necessario però prima specificare cosa si intenda per migliore: in questo caso, considereremo come criterio di scelta quello dell’errore quadratico medio, ovvero la discrepanza media fra i valori dei dati osservati e i valori stimati; un risultato sarà tanto migliore quanto più renderà piccolo questo valore.
Torniamo all’esempio del baseball e consideriamo le medie di battuta di 18 giocatori di prima divisione, calcolate dopo le prime 45 battute. La media in questo caso è definita come il numero di volte in cui un giocatore è riuscito a battere diviso per il totale; indichiamo ciascuna di queste 18 medie con la lettera y. A questo punto calcoliamo la media tra le medie di questi valori e la indichiamo con y, termine che Bradley ed Efron battezzano grande media.
Il paradosso di Stein ci dice che c’è un modo migliore dell’usare la media dei singoli giocatori per prevedere la media battute a fine campionato, e per farlo si utilizza quello che viene chiamato stimatore di James-Stein. Per ogni giocatore, tale stimatore assume il seguente valore: z = y + c(y-y).
La quantità (y-y) non è altro che la differenza fra la media del singolo giocatore e quella di tutti. Nella sostanza, la quantità z differisce dalla grande media del termine (y-y) moltiplicato per un fattore c, noto in inglese come shrinkage ovvero restringimento/contrazione.
Non entriamo nel dettaglio del calcolo per la determinazione di c, ma assumiamo per semplicità che corrisponda a un determinato valore sempre minore di uno. Nell’esempio proposto da Efron e Morris lo shrinkage vale 0,212 mentre la grande media vale 0,265.
A questo punto ci chiediamo rispetto a cosa poter confrontare i valori ottenuti da questo stimatore. Infatti, per farlo con precisione dovremmo conoscere la vera abilità di battuta di ogni giocatore, quantità che però non è osservabile direttamente. Non c’è da scoraggiarsi, possiamo fare l’ipotesi di usare tutte le rimanenti partite della stagione di baseball, che sono una quantità di osservazioni di gran lunga superiore rispetto a quelle delle prime 45 battute. Utilizzando questi dati, si calcola che lo stimatore di James-Stein è il migliore, nel senso che produce un errore quadratico medio più piccolo. La media non è il modo migliore per descrivere una grandezza!
Adesso aggiungiamo un ulteriore aspetto che renderà il paradosso ancora più bizzarro. Riutilizziamo l’esempio del baseball tratto dall’articolo: immaginiamo di essere negli anni Settanta e di voler stimare la percentuale di automobili straniere a Chicago. Prendendo un campione casuale di automobili osserviamo che solo 9 delle 45 osservate sono di fabbricazione estera, quindi possiamo stimare il numero tramite la media, 9/45 del totale. Se però immaginiamo di avere a disposizione i dati precedenti del baseball si possono associare i due problemi, un po’ come se la percentuale di auto straniere fosse un diciannovesimo giocatore di baseball, per calcolare lo stimatore di James-Stein e ottenere una stima migliore. Nel teorema di Stein non c’è nulla che richieda un legame fra i vari problemi, quindi il passaggio è legittimo, anche se ha sollevato critiche di diverso tipo; comunque, converrete che questo fatto è decisamente poco intuitivo.
Note
1) Bradley Efron, Carl N. Morris, Stein's Paradox in Statistics, Scientific American 236(5):119-127, 1977.
Riferimenti bibliografici
- Stein, C. (1956). "Inadmissibility of the usual estimator for the mean of a multivariate distribution". Proceedings of the Third Berkeley Symposium on Mathematical Statistics and Probability. 1. pp. 197–206. MR 0084922.
- James, W., Stein C. (1961). “Estimation with quadratic loss”. Proceedings of the Fourth Berkeley Symposium on Mathematical Statistics and Probability, 1, 361–380.