Con il termine “fake news”, secondo l’enciclopedia Treccani[1], si designa un’informazione in parte o del tutto non corrispondente al vero, divulgata intenzionalmente o inintenzionalmente attraverso il Web, i media o le tecnologie digitali di comunicazione, e caratterizzata da un’apparente plausibilità, quest’ultima alimentata da un sistema distorto di aspettative dell’opinione pubblica e da un’amplificazione dei pregiudizi che ne sono alla base.
Il boom dei social network, congiuntamente alla possibilità di essere sempre connessi mediante smart device (smartphone, tablet, wearable), ha contribuito a una larga diffusione di fake news, create e rilasciate prevalentemente per fini commerciali e/o politici.
Il fenomeno delle fake news è salito alla ribalta della cronaca mondiale a partire dal 2016, a seguito delle votazioni per le presidenziali americane e del referendum sulla Brexit. Secondo alcuni studi, infatti, gli esiti di queste consultazioni sarebbero stati influenzati proprio dalla diffusione di notizie false durante le rispettive campagne elettorali. Un’analisi[2], condotta da due economisti, rispettivamente della Stanford e della New York University, ha mostrato come durante la campagna presidenziale le fake news in favore di Donald Trump siano state condivise fino a 30 milioni di volte, circa il quadruplo rispetto a quelle circolate in favore di Hillary Clinton. Questo dato è in linea con quanto emerso da un secondo studio[3], condotto da economisti della Ohio University, in cui si afferma che proprio le fake news potrebbero aver avuto un ruolo importante nell’elezione di Trump, andando a influenzare la percezione degli elettori.
Contro la diffusione delle fake news si sono mobilitati non solo il mondo accademico e della ricerca, ma anche i governi nazionali e/o comunitari. In tutto il mondo sono nate diverse associazioni, anche no-profit, di “Fact Checking”, ovvero di verifica delle notizie, per aiutare a riconoscere - attraverso la verifica puntuale dei fatti - possibili notizie false, o anche parzialmente inesatte.
Persino big della tecnologia come Google, Facebook e Twitter, che basano buona parte del loro business (se non tutto) sui contenuti, sono scesi in campo arrivando alla sottoscrizione di codici di condotta[4] e all’investimento di ingenti risorse volte a combattere la diffusione di questo fenomeno.
Facebook, ad esempio, per arginare la diffusione di fake news, ha applicato una strategia ibrida, capace di integrare l’intelligenza artificiale con quella umana, per arrivare a individuare possibili fake news, veicolate anche mediante immagini o video[5].
Considerata la quantità di informazioni prodotta e condivisa giornalmente sui social network, anche ipotizzando di avere un elevato numero di risorse, è impensabile supporre di poter risolvere il problema mediante un controllo umano puntuale. Per effettuare dei controlli massivi, è quindi necessario ricorrere a sistemi automatici, basati sull’intelligenza artificiale e in particolare su tecniche di deep learning.
Il deep learning è una nuova branca del machine learning (e quindi dell’intelligenza artificiale) che si avvale di reti neurali complesse, composte di molteplici strati (layer) e che in pochissimo tempo ha saputo superare i risultati ottenuti con le metodologie classiche (Classificatori Naive Bayes, SVM, Random Forest, ecc.). Le reti neurali artificiali, ricalcando il funzionamento di quelle biologiche, sono composte di molteplici neuroni. 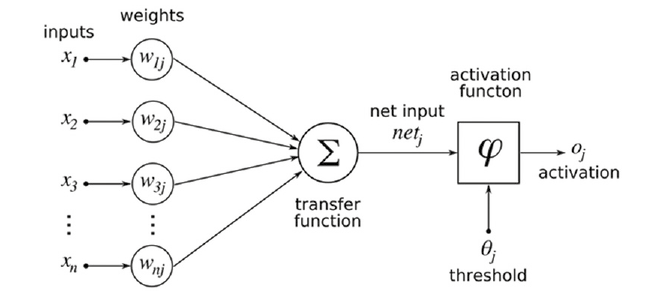 Un neurone artificiale (Figura 1) è una funzione matematica capace di ricevere molteplici input xi, combinarli linearmente con pesi wij e passarli attraverso una funzione di trasformazione (∑ lineare o non lineare) per decidere infine, mediante l’applicazione di una funzione di attivazione (ϕ), se il neurone debba attivarsi oppure no. Il modo in cui i vari neuroni sono collegati tra loro e il numero di layer presenti definiscono la topologia della rete neurale. Topologie differenti possono essere utilizzate per assolvere a specifici compiti. Ad esempio, le Convolutional Neural Network (CNN) hanno mostrato ottime performance nell’analisi di immagini. In Figura 2 sono mostrate le principali topologie di rete.
Un neurone artificiale (Figura 1) è una funzione matematica capace di ricevere molteplici input xi, combinarli linearmente con pesi wij e passarli attraverso una funzione di trasformazione (∑ lineare o non lineare) per decidere infine, mediante l’applicazione di una funzione di attivazione (ϕ), se il neurone debba attivarsi oppure no. Il modo in cui i vari neuroni sono collegati tra loro e il numero di layer presenti definiscono la topologia della rete neurale. Topologie differenti possono essere utilizzate per assolvere a specifici compiti. Ad esempio, le Convolutional Neural Network (CNN) hanno mostrato ottime performance nell’analisi di immagini. In Figura 2 sono mostrate le principali topologie di rete. 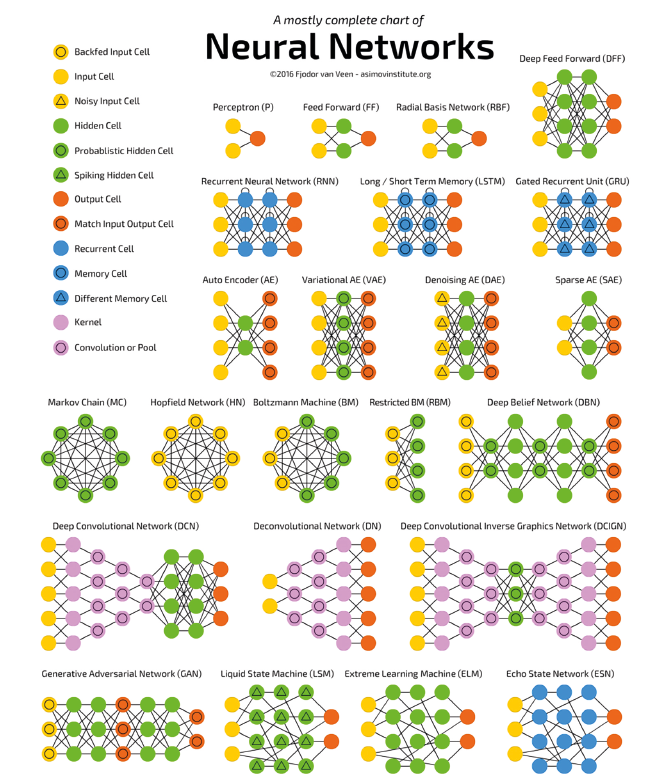
Da un punto di vista tecnico-scientifico, decidere se un contenuto, testuale o di altro tipo, rappresenti una fake news oppure no è assimilabile a un problema di classificazione, dunque non è concettualmente differente dal riconoscimento dello spam o dall’analisi del sentiment, ovvero dalla capacità di comprendere se nei messaggi degli utenti sono presenti opinioni positive, negative o neutre. Partendo da questa assunzione ricercatori ed esperti hanno iniziato ad approcciare il problema del riconoscimento delle fake news, sfruttando modelli di classificazione utilizzati in contesti simili, ma opportunamente modificati per adattarli alle peculiarità di questo specifico compito.
Per poter imparare a distinguere una fake news rispetto ad altri contenuti, gli algoritmi di classificazione devono essere addestrati. Questa fase di apprendimento prende il nome di “training del modello” e necessita di numerosi esempi (training set): sia di casi positivi (fake news) che negativi (normali contenuti). Elaborando il training set, il modello impara come riconoscere le caratteristiche peculiari (feature) delle fake news, riuscendo così a distinguerle dai normali contenuti.
Nell’ambito delle fake news sono state individuate due macro-categorie di feature:
Nella prima macro-categoria rientrano tutte le caratteristiche derivanti dal canale social attraverso cui il contenuto è stato prodotto e propagato, come il profilo dell’autore e degli utenti che hanno contribuito alla sua diffusione mediante like, condivisioni, commenti, tag di altri utenti, ecc.
La seconda macro-categoria, invece, può contenere caratteristiche differenti in funzione che si stia analizzando del testo, oppure video o immagini. Nel primo caso, infatti, saranno prese in considerazione caratteristiche linguistiche, sia a livello statistico-lessicale, sia a livello sintattico-semantico. Per le caratteristiche lessicali si andranno a considerare, ad esempio, il numero di parole, la lunghezza media delle stesse, le parole ricorrenti e/o uniche, mentre per le caratteristiche sintattico-semantiche si analizzerà il ruolo che la parola ricopre nel testo, la co-occorrenza di parole che possono assumere un significato specifico rispetto a quando occorrono singolarmente[6], il sentiment, ovvero la presenza di opinioni positive o negative, ecc. Per quanto riguarda video e immagini, invece, le caratteristiche considerate possono essere di tipo visivo (score di coerenza, score di diversità, istogrammi di distribuzione della similarità) oppure di tipo statistico come il rapporto tra le dimensioni dell’immagine.
Durante la fase di training, gli algoritmi di classificazione imparano a identificare il presentarsi di un insieme di feature ricorrenti (pattern) e comuni agli esempi di fake news presenti nel training set. Questa conoscenza, memorizzata all’interno del modello, può quindi essere utilizzata dall’algoritmo per analizzare i contenuti prodotti dagli utenti reali e classificarli rispetto alla categoria di appartenenza. Durante la classificazione i nuovi contenuti sono analizzati per individuare la presenza dei pattern (tutti o alcuni) appresi dal modello e stimare la probabilità che le combinazioni individuate possano identificare una fake news.
L’efficacia delle iniziative messe in campo da Facebook in questi anni, per prevenire la pubblicazione e la condivisione di fake news, è stata oggetto di indagine in un recente studio[7] condotto da due professori, di Stanford e New York University, che hanno analizzato il volume di interazioni[8] rispetto alle fake news circolate su Facebook nel periodo Gennaio 2015-Luglio 2018 negli Stati Uniti.
Nello studio sono stati confrontati il volume di interazioni con news provenienti da fonti “non attendibili” e il volume di interazioni con news provenienti da fonti sicure.
Per le news provenienti da fonti sicure, il volume di interazioni prodotte è stato stabile durante tutto il periodo in esame, mentre la quantità di interazioni contenenti fake news è cresciuta costantemente dall’inizio del 2015 fino alle elezioni del 2016. Successivamente alle elezioni, invece, le interazioni su Facebook si sono ridotte a più della metà.
Questo indica che le azioni messe in campo da Facebook hanno portato a dei buoni risultati, che non sono però sufficienti considerato l’elevato numero di fake news ancora in circolazione (a Luglio 2018 risultavano ancora circa 70 milioni solo negli Stati Uniti). In quest’ottica va inquadrata la conferma data da Facebook a Luglio 2018 dell'acquisizione di Bloomsbury.ai[9], una startup con sede a Londra specializzata nella realizzazione di sistemi automatici per l’analisi del testo. Un ulteriore segnale nel contrasto attivo al fenomeno delle fake news arriva anche dalla Comunità Europea. È di fine novembre, infatti, la notizia della nascita del progetto Fandango[10], un’iniziativa finanziata nell’ambito di Horizon Europe, che punta a usare l’intelligenza artificiale per contrastare le fake news.
Tuttavia la lotta al problema delle fake news non può ricondursi alla sola definizione di una serie di algoritmi in grado di stabilire se una notizia sia vera o meno. La ricerca delle cause e delle possibili soluzioni al problema va affrontata anche su un piano socio-culturale, oltre che tecnologico.
Il problema della disinformazione trova terreno fertile nel contesto sociale in cui ci troviamo, caratterizzato da una diffusa mancanza di fiducia verso le istituzioni e i media classici e da un elevato livello di analfabetismo funzionale[11] e di ritorno[12] in tutto il mondo. I tentativi di smascherare una fake news (debunking) spesso rafforzano la credenza in essa da parte dei suoi sostenitori e sono addirittura visti come azioni di censura.
Infatti, come emerge da una recente di indagine dell’AGCOM[13], “gli utenti tendono a selezionare le informazioni che sono coerenti con il loro sistema di credenze, formando gruppi polarizzati di persone con idee simili su narrazioni condivise, in cui le informazioni discordanti vengono ignorate, rendendo spesso inutili i tentativi di debunking”.
Come si può uscire da questo circolo vizioso? Secondo il Garante della Privacy, Antonello Soro, è necessario[14]: «un articolato e complesso impegno pubblico e privato nell´educazione civica alla società digitale e al pensiero critico [che conduca a]…una sistematica verifica delle fonti e una forte assunzione di responsabilità da parte di ciascuno».
In attesa, quindi, che nuovi sistemi di Intelligenza Artificiale raggiungano performance tali da garantire la veridicità delle informazioni, la Figura 3 mostra un’immagine, realizzata dall’IFLA[15] (International Federation of Library Associations and Institutions), che descrive 8 semplici regole che ognuno dovrebbe sempre applicare, per valutare la veridicità del contenuto che sta leggendo. 
Il boom dei social network, congiuntamente alla possibilità di essere sempre connessi mediante smart device (smartphone, tablet, wearable), ha contribuito a una larga diffusione di fake news, create e rilasciate prevalentemente per fini commerciali e/o politici.
Il fenomeno delle fake news è salito alla ribalta della cronaca mondiale a partire dal 2016, a seguito delle votazioni per le presidenziali americane e del referendum sulla Brexit. Secondo alcuni studi, infatti, gli esiti di queste consultazioni sarebbero stati influenzati proprio dalla diffusione di notizie false durante le rispettive campagne elettorali. Un’analisi[2], condotta da due economisti, rispettivamente della Stanford e della New York University, ha mostrato come durante la campagna presidenziale le fake news in favore di Donald Trump siano state condivise fino a 30 milioni di volte, circa il quadruplo rispetto a quelle circolate in favore di Hillary Clinton. Questo dato è in linea con quanto emerso da un secondo studio[3], condotto da economisti della Ohio University, in cui si afferma che proprio le fake news potrebbero aver avuto un ruolo importante nell’elezione di Trump, andando a influenzare la percezione degli elettori.
Contro la diffusione delle fake news si sono mobilitati non solo il mondo accademico e della ricerca, ma anche i governi nazionali e/o comunitari. In tutto il mondo sono nate diverse associazioni, anche no-profit, di “Fact Checking”, ovvero di verifica delle notizie, per aiutare a riconoscere - attraverso la verifica puntuale dei fatti - possibili notizie false, o anche parzialmente inesatte.
Persino big della tecnologia come Google, Facebook e Twitter, che basano buona parte del loro business (se non tutto) sui contenuti, sono scesi in campo arrivando alla sottoscrizione di codici di condotta[4] e all’investimento di ingenti risorse volte a combattere la diffusione di questo fenomeno.
Facebook, ad esempio, per arginare la diffusione di fake news, ha applicato una strategia ibrida, capace di integrare l’intelligenza artificiale con quella umana, per arrivare a individuare possibili fake news, veicolate anche mediante immagini o video[5].
Come l’Intelligenza Artificiale può essere d’aiuto
Considerata la quantità di informazioni prodotta e condivisa giornalmente sui social network, anche ipotizzando di avere un elevato numero di risorse, è impensabile supporre di poter risolvere il problema mediante un controllo umano puntuale. Per effettuare dei controlli massivi, è quindi necessario ricorrere a sistemi automatici, basati sull’intelligenza artificiale e in particolare su tecniche di deep learning.
Il deep learning è una nuova branca del machine learning (e quindi dell’intelligenza artificiale) che si avvale di reti neurali complesse, composte di molteplici strati (layer) e che in pochissimo tempo ha saputo superare i risultati ottenuti con le metodologie classiche (Classificatori Naive Bayes, SVM, Random Forest, ecc.). Le reti neurali artificiali, ricalcando il funzionamento di quelle biologiche, sono composte di molteplici neuroni.
Figura 1. Schema di un neurone artificiale
Figura 2. Topologie di Reti Neurali
Da un punto di vista tecnico-scientifico, decidere se un contenuto, testuale o di altro tipo, rappresenti una fake news oppure no è assimilabile a un problema di classificazione, dunque non è concettualmente differente dal riconoscimento dello spam o dall’analisi del sentiment, ovvero dalla capacità di comprendere se nei messaggi degli utenti sono presenti opinioni positive, negative o neutre. Partendo da questa assunzione ricercatori ed esperti hanno iniziato ad approcciare il problema del riconoscimento delle fake news, sfruttando modelli di classificazione utilizzati in contesti simili, ma opportunamente modificati per adattarli alle peculiarità di questo specifico compito.
Per poter imparare a distinguere una fake news rispetto ad altri contenuti, gli algoritmi di classificazione devono essere addestrati. Questa fase di apprendimento prende il nome di “training del modello” e necessita di numerosi esempi (training set): sia di casi positivi (fake news) che negativi (normali contenuti). Elaborando il training set, il modello impara come riconoscere le caratteristiche peculiari (feature) delle fake news, riuscendo così a distinguerle dai normali contenuti.
Nell’ambito delle fake news sono state individuate due macro-categorie di feature:
- basate sul contesto social
- basate sul contenuto
Nella prima macro-categoria rientrano tutte le caratteristiche derivanti dal canale social attraverso cui il contenuto è stato prodotto e propagato, come il profilo dell’autore e degli utenti che hanno contribuito alla sua diffusione mediante like, condivisioni, commenti, tag di altri utenti, ecc.
La seconda macro-categoria, invece, può contenere caratteristiche differenti in funzione che si stia analizzando del testo, oppure video o immagini. Nel primo caso, infatti, saranno prese in considerazione caratteristiche linguistiche, sia a livello statistico-lessicale, sia a livello sintattico-semantico. Per le caratteristiche lessicali si andranno a considerare, ad esempio, il numero di parole, la lunghezza media delle stesse, le parole ricorrenti e/o uniche, mentre per le caratteristiche sintattico-semantiche si analizzerà il ruolo che la parola ricopre nel testo, la co-occorrenza di parole che possono assumere un significato specifico rispetto a quando occorrono singolarmente[6], il sentiment, ovvero la presenza di opinioni positive o negative, ecc. Per quanto riguarda video e immagini, invece, le caratteristiche considerate possono essere di tipo visivo (score di coerenza, score di diversità, istogrammi di distribuzione della similarità) oppure di tipo statistico come il rapporto tra le dimensioni dell’immagine.
Durante la fase di training, gli algoritmi di classificazione imparano a identificare il presentarsi di un insieme di feature ricorrenti (pattern) e comuni agli esempi di fake news presenti nel training set. Questa conoscenza, memorizzata all’interno del modello, può quindi essere utilizzata dall’algoritmo per analizzare i contenuti prodotti dagli utenti reali e classificarli rispetto alla categoria di appartenenza. Durante la classificazione i nuovi contenuti sono analizzati per individuare la presenza dei pattern (tutti o alcuni) appresi dal modello e stimare la probabilità che le combinazioni individuate possano identificare una fake news.
Cosa si è fatto e cosa rimane da fare
L’efficacia delle iniziative messe in campo da Facebook in questi anni, per prevenire la pubblicazione e la condivisione di fake news, è stata oggetto di indagine in un recente studio[7] condotto da due professori, di Stanford e New York University, che hanno analizzato il volume di interazioni[8] rispetto alle fake news circolate su Facebook nel periodo Gennaio 2015-Luglio 2018 negli Stati Uniti.
Nello studio sono stati confrontati il volume di interazioni con news provenienti da fonti “non attendibili” e il volume di interazioni con news provenienti da fonti sicure.
Per le news provenienti da fonti sicure, il volume di interazioni prodotte è stato stabile durante tutto il periodo in esame, mentre la quantità di interazioni contenenti fake news è cresciuta costantemente dall’inizio del 2015 fino alle elezioni del 2016. Successivamente alle elezioni, invece, le interazioni su Facebook si sono ridotte a più della metà.
Questo indica che le azioni messe in campo da Facebook hanno portato a dei buoni risultati, che non sono però sufficienti considerato l’elevato numero di fake news ancora in circolazione (a Luglio 2018 risultavano ancora circa 70 milioni solo negli Stati Uniti). In quest’ottica va inquadrata la conferma data da Facebook a Luglio 2018 dell'acquisizione di Bloomsbury.ai[9], una startup con sede a Londra specializzata nella realizzazione di sistemi automatici per l’analisi del testo. Un ulteriore segnale nel contrasto attivo al fenomeno delle fake news arriva anche dalla Comunità Europea. È di fine novembre, infatti, la notizia della nascita del progetto Fandango[10], un’iniziativa finanziata nell’ambito di Horizon Europe, che punta a usare l’intelligenza artificiale per contrastare le fake news.
Tuttavia la lotta al problema delle fake news non può ricondursi alla sola definizione di una serie di algoritmi in grado di stabilire se una notizia sia vera o meno. La ricerca delle cause e delle possibili soluzioni al problema va affrontata anche su un piano socio-culturale, oltre che tecnologico.
Il problema della disinformazione trova terreno fertile nel contesto sociale in cui ci troviamo, caratterizzato da una diffusa mancanza di fiducia verso le istituzioni e i media classici e da un elevato livello di analfabetismo funzionale[11] e di ritorno[12] in tutto il mondo. I tentativi di smascherare una fake news (debunking) spesso rafforzano la credenza in essa da parte dei suoi sostenitori e sono addirittura visti come azioni di censura.
Infatti, come emerge da una recente di indagine dell’AGCOM[13], “gli utenti tendono a selezionare le informazioni che sono coerenti con il loro sistema di credenze, formando gruppi polarizzati di persone con idee simili su narrazioni condivise, in cui le informazioni discordanti vengono ignorate, rendendo spesso inutili i tentativi di debunking”.
Come si può uscire da questo circolo vizioso? Secondo il Garante della Privacy, Antonello Soro, è necessario[14]: «un articolato e complesso impegno pubblico e privato nell´educazione civica alla società digitale e al pensiero critico [che conduca a]…una sistematica verifica delle fonti e una forte assunzione di responsabilità da parte di ciascuno».
In attesa, quindi, che nuovi sistemi di Intelligenza Artificiale raggiungano performance tali da garantire la veridicità delle informazioni, la Figura 3 mostra un’immagine, realizzata dall’IFLA[15] (International Federation of Library Associations and Institutions), che descrive 8 semplici regole che ognuno dovrebbe sempre applicare, per valutare la veridicità del contenuto che sta leggendo.
Figura 3. 8 regole per valutare la veridicità di un contenuto
Note
6) Le parole “casa” e “bianca” ad esempio hanno significati ben specifici, ma quando co-occorrono vicine all’interno di una frase, possono assumere un nuovo significato, andando a individuare un’entità geo-politica ben precisa e non una semplice abitazione di colore bianco.
8) Nell’articolo, per interazione si intende l’insieme di commenti, condivisioni e reazioni a un singolo post.
11) L’incapacità di comprendere il significato di ciò che si legge.
12) L'analfabetismo di ritorno è quel fenomeno attraverso il quale un individuo che abbia assimilato nel normale percorso scolastico di alfabetizzazione le conoscenze necessarie alla scrittura e alla lettura perde nel tempo quelle stesse competenze, a causa del mancato esercizio di quanto imparato.